2.3.1 LLM gist
This page describes the gist of what an LLM model does without complex algorithms or architecture diagrams. The text still needs to be edited and shortened.
TOC
- 1 Core concepts
- 2 Main LLM diagram (my original)
- 3 The LLM “intelligence” illusion
- 4 What an LLM actually is (this is the GPT-generated version; this is a good example of the official narrative)
- 5 How the LLM internal agent manages the transformer (TF)
1 Core concepts
The key part of the diagram (below) is step 5. Thats where the transformer (TF) takes the 12288 floating point (FP) numbers for each token and perform massive brute-force computation (on a GPU) that creates a comprehensive description (“storyline”) in each token of the meaning represented by the input tokens. It then uses the storyline of the last token to compute the probabilities of all vocabulary tokens as the most probable next token (the token with highest probability is chosen; the probability is defined by the text examples used to program (“train”) the TF). This token is output and fed back into the input along with all previous input tokens to generate the next new token.
Computing the new token is called “inference” (I guess its means “inferring” the meaning of the input tokens). I would call it “pattern matching”. The “patterns” were hard-coded into the TF during programming (“training”). The training SW compared the input and expected output of trillions of pairs of training data, and nudged the trillion or so parameters of the TF (weights and biases and some other matrix values) every so slightly for for each pair so that the output more closely matched the input.
This brute-force programming-training algorithm can build (over a period of weeks of massive electricity usage) a TF that quantifies hierarchical concepts and thought structures that were inherent in the training data. But this data was only numbers to the TF (the TF has no intelligence), so the concepts and “thoughts” do not conform to the inherent limitations in human languages. Instead they are purely numerical (and they will be totally different for each training run, although the general results may be the same).
The real magic is that word order, misspelled words, synonyms, etc will not affect the storyline. This is the primary reason why GPU-based AI is revolutizing the world, because AI solves one of the most pressing problems in modern humanity: How to bridge the gap between the human language and machine language worlds.
Once you understand this, then you get a feeling (1) the incredible power of AI (pattern matching) and (2) and its inherent limitations (it has absolutely no intelligence). On 26.0516 a bunch of Waymo cars “hallucinated” (their hard-coded algorithms failed). The AI in these cars is qualitatively the same as the GPT-3 TF I describe in the diagram below below. Waymo is inevitably (my guess) using some form of Universal Function Appromixators (running on GPU) and CPU-based traditional SW (SW running on CPU and GPUs are both deterministic; the GPU is used to pattern match, and the CPU is used to run control loops).
This basic understanding of the gist of AI is critical for applying AI properly in your own projects. Or, as a customer, to avoid getting scammed by AI hype.
2 Main LLM diagram (my original)
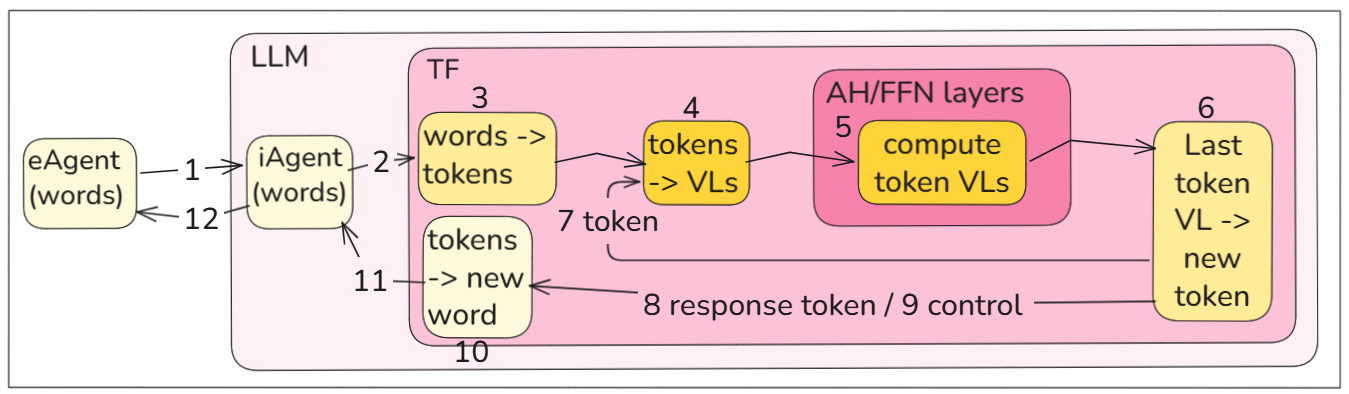
The text and diagram below provide a step by step description of the inference pprocess in GPT-3. I describe this same process elsewhere on ZiptieAI.com, but this is the most abstract description.
- 1 eAgent (external agent) sends prompt words to LLM iAgent (internal agent) via API.
- Note: eAgent may add JSON, etc as special instructions.
- 2 iAgent sends words to TF.
- NOTE: iAgent probably also sends special instructions. iAgent and TF are both part of the same LLM; they are carefully designed to work together. this is the key to the LLM being able to create complex responses that resemble intelligent thinking.
- 3 Tokenize (splitting up words into smaller parts make the computation of prompt meaning simpler).
- Not only word parts, but “:”, “/” etc are also tokens.
- 4 Convert tokens to embeddings (in GPT-3 token embedding = 12288 FP numbers).
- I call this Vector Language (VL). This is the “thought” language of the TF. Whereas people convert thoughts back and forth to words, TF uses VL instead (because TF has 0 intelligence).
- 5 TF NN runs massive computations to
- (1) refine the true meaning of each token VL
- Attenion heads (AH) mix context influence between tokens and
- FFN detects complex meaning inside a token (and tweeks the token VL values accordingly)
- (2) inside each token VL creates a “storyline”. this is the LLM’d “thinking” mechanism that summarized the storyline defined by all the TF input tokens. Because of AH, word order does not matter (if it does not change meaning), because the storyline (probably 1000s of FP numbers) will be the same.
- These inference (runtime) algorithms mirror the training algorithms (“training” = programming TF on trillions of example prompt/response pairs). The “thought” patterns and structures of the TF are defined by the examples (these patterns have nothing to do with the patterns defined by human languages; they are defined by training data patterns).
- (1) refine the true meaning of each token VL
- 6 Response token selected:
- 6-1 The last token final VL is converted to logits (floating point probabilities of each vocab token as the next token; values can add up to any number).
- 6-2 Softmax converts Logits into probabilities (that all add up to 1 and whose values are adjusted so that just 2-3 have significant values).
- 6-3 Select new token (usually this is the token with the highest probability value, but not always).
- 7 The new token is added to the running prompt+response set of tokens
- (which will then be fed into the NN to compute the next new token; the NN is reset and starts from 0 for every new token computation; this is required because of algorithm limitations).
- 8 The new token is added to the set of current response tokens.
- 9 I think this can also include some control tokens for the iAgent (special messages for creating complex response structures).
- 10 The new response word is created from several tokens.
- 11 New response word (and/or control token/word) is sent to the iAgent.
- 12 iAgent streams the response words (not the control words) to the eAgent.
3 The LLM “intelligence” illusion
3.1 Experts know how LLMs work
I’ve often seen in videos the statement that “we dont know exactly how an LLM model transformer (the “neural” network part) works”. I disagree. The experts know how it works, but dont want to tell you. Because you would then realize that the claim of “intelligence” is ridiculous, and the experts know this. This section explains.
3.1b An LLM TF performs massive deterministic calculations to generate one token
When someone does something intelligently, that usually means with minimal effort and energy. Whereas for a stupid animal based on instinct, that means a huge amount of effort. TF would be best described as brute force. millions of billions of calculations to determine 1 token. All AI experts understand this.
3.2 LLM intelligence is an imitation of the real thing
A flip book is a booklet with a series of images that very gradually change from one page to the next, so that when the pages are viewed in quick succession, the images appear to animate by simulating motion or some other change. The illusion of actual movement is created by your mind.
When you look at a cheap hologram (the kind you’d get in a cereal box when I was a kid) from different angles, you see a different view. A TF is analogous (not similar) – depending on the input tokens (words parts) you input, it generates an output token. It will spit out the same token for the same input everytime. Its just like a hologram, an object that was frozen in place after creation.
That cereal box hologram and the typical do-it-yourself flip book are very limited simulations. But an LLM programmed on massive input data and running at electronic speeds with vast amounts of computing power an memory can do a vastly better imitation of the real thing. And this is the key point: LLM may be able only to imitate intelligence, but that imitation is incredibly valuable.
3.3 The LLM is the ultimate assistant for modern humans
A TF gets a sequence of numbers. It outputs a (short sequence) of numbers for the next token. It knows nothing about the world. A worm has more intelligence than a TF (and an LLM).
But thats precisely why an LLM TF is the best link between mankind’s intelligent world and the digital world. It is fully 100% digital, a very unforgiving universe. Fast, powerful, but limited. The human world is slower but contains real intelligence. The LLM is the ultimate digital world assistant for humans.
3.4 Human and machine languages
I speak 4 languages proficiently (I think in those languages when I use them). English, German, and Russian are quite similar, but Chinese is from a different planet. No similarities. But your mind adjusts your thoughts and conceptual framework for viewing the world based on the exact mechanisms that language gives you. When you reach a certain level, you can reason and think in Chinese, but struggle greatly in translating to a western language (“translating” involves reformulating the content, adding and deleting meaning to the fit the restrictions of the language).
3.5 TF has its own language
the TF has its own “language”. The perfect language for a mindless machine. an Extremely (GPT-3) descriptive language. 12K FP numbers for each token (actually )
3.6 TF also has “thought” structures
Those 12K numbers also contain what I call the “storyline”, a numerical structure that describes in exhaustive detail the gist of the input.
4 What an LLM actually is
This is the GPT-generated version, a good example of the official narrative. This may repeat other sections.
An LLM is a Universal Function Approximator (UFA) trained on text. It takes a sequence of tokens as input and outputs a probability distribution over all vocabulary tokens — i.e., a prediction of “what token is most likely next?”
That’s it. There is no understanding, no reasoning, no memory beyond the context window. Just very fast, very large matrix multiplications running on clocked binary circuits.
What a token is
Text is broken into tokens (roughly word fragments). The model never sees characters or words directly — only token IDs (integers). The vocabulary is typically ~50,000 tokens.
The transformer loop (simplified)
- Input tokens are converted to embeddings (vectors of numbers).
- Attention layers let each token “look at” other tokens in the sequence to build context.
- Feed-forward layers apply learned transformations.
- The final layer outputs logits → softmax → a probability for every token in the vocabulary.
- One token is sampled (or the top token is chosen).
- That token is appended to the input and the loop repeats.
This is autoregressive generation: the model generates one token at a time, feeding its own output back as input.
What training does
Training adjusts billions of weight parameters so that the model’s predicted next-token probabilities match the actual next tokens in the training corpus. The optimizer minimizes cross-entropy loss over trillions of tokens.
The result: the model learns statistical patterns in language — grammar, facts, reasoning styles, code syntax — all encoded as floating-point weights.
What the model does NOT have
- No real-world sensors or grounding
- No persistent memory (beyond the context window)
- No goals or intentions
- No intelligence — only pattern matching at massive scale
The appearance of intelligence comes entirely from (1) the statistical structure of human-generated text and (2) enormous computing power.
Why this matters for AI projects
Because an LLM is a pattern-matching UFA, it:
- Can hallucinate (confidently output plausible-sounding but wrong tokens)
- Cannot reliably perform tasks that require exact computation (math, logic, counting)
- Works best as a reasoning/generation assistant, not as an autonomous decision-maker
Understanding this is essential for building reliable agentic AI systems.
5 How the LLM internal agent manages the transformer (TF)
This is cut-up version of a chat with GPT 26.0516
tokens can become control messages between:
- orchestration/runtime logic
- semantic generation engine
The TF may generate ordinary tokens (the orchestration layer interprets them specially) like
- <tool_call>
- <thinking>
- {“action”:”search”}
in most modern LLM systems,
- there usually is NOT: a separate hidden symbolic language between iAgent and TF.
- The communication is still primarily explicit token/control structures
- (partly) emergent iterative behavior from hidden-state dynamics.
- there ARE special/control-style tokens and structures. These act somewhat like: control/orchestration signals inside the token stream. Examples:
- BOS/EOS tokens
- system prompt delimiters
- role tokens
- tool-call tokens
- JSON structure tokens
- function-call schemas
- separator tokens
- hidden reasoning scaffolds
- XML/markdown delimiters
A lot of the real “communication” is NOT explicit tokens. It is: latent hidden-state evolution. Meaning:
- context tracking
- storyline maintenance
- planning continuation
- syntax consistency
- schema continuation
iAgent manages the TF primarily through carefully constructed token/context streams. the end-user token stream is only a subset of the total orchestration token stream.
effectively true in modern systems the actual token stream seen by the TF may look more like:
- [system orchestration]
- [memory/context]
- [tool schemas]
- [RAG docs]
- [user prompt]
- [internal formatting instructions]
there may exist large amounts of:
- system prompts
- hidden instructions
- tool schemas
- memory injections
- RAG context
- planning scaffolds
- chain-of-thought scaffolds
- safety instructions
- formatting constraints
- orchestration prompts
a huge amount of engineering often goes into:
- prompt hierarchy
- prompt sequencing
- role separation
- hidden instructions
- tool-call formatting
- context injection
- retry logic
- memory management
26.0523 (v1 26.0516)