2.3.2 Gist of LLM TF UFA (inference)
This page (WORK IN PROGRESS) shows selected screenshots from the wiki page Core AI concepts (explains in detail GPT-3 transformer algorithms). These diagrams depict my interpretation of the GPT-3 algorithm.
TOC: TF algorithm
- 1 Summary
- 2 Diagrams
- 3 Math
1 TF UFA Summary
1.1 GPT-3 TF UFA
A TF implements a Univeral Function Approximator (UFA) algorithm. Understanding what a UFA is is the key to understanding what AI really is. This section talks about the GPT-3 TF. Newer models may be much more powerful, but the core techniques they use to implement a UFA will be similar.
1.2 TF is the only HL interface
- The LLM TF UFA is the only practical interface between human language and computers. An LLM transformer (TF) is a Universal Function Approximator (UFA). This word suggests that an LLM (TF + internal agent) is not intelligent. Therefore Agentic AI (deterministic Python agent + LLM) must be designed carefully to work reliably and safely.
- The only binary-based computers can process human language (HL) is to implement a UFA for massive brute force computational analysis (thus GPUs instead of CPUs; theoretically you could use a CPU for any GPU task, but it would be vastly slower).
1.3 TF is 100% deterministic, similar to CNN algo
- A TF performs computational pattern matching.
- TF takes the convolution/max-pooling concept in CNNs and duplicates the same idea for language in TF as Attention-heads/softmax.
- A TF UFA is 100% deterministic. There is a very mistaken idea that GPUs are not deterministic like CPUs. They are. For basic info, watch this:
- ByteMonk released (26.0510 ) a fantastic video that clearly describes how GPUs operate (Google’s New TPU Quietly Ends the GPU Era?).
- In the future, I will start using “GPU-based” and “CPU-based” to distinguish betweed the AI and the agentic parts of apps (“deterministic” is a misleading misnomer).
1.4 Vector Language
- TF converts each (1) Human Language (HLang) input (prompt) into (2) Vector Language (VLang). You have to use VL because human printed languages are just primitive hints designed for intelligent humans to communicate complex concepts. Word combinations can be almost infinite, with all kind of spelling mistakes, abbreviations, bad grammar, etc etc. You can never create a DB of all possible combinations.
- The UFA works by converting input tokens (word parts, “Human Language (HL)”) into numbers (what I call “vector language” (VL)). The UFA has no concept of anything but numbers.
1.5 Storyline
- The VLang for each prompt is refined into a “storyline”.
- The (3) storyline of the last token is used to determine the vocab token that most closely matches what has been programmed into the NN for the current input.
- The UFA then performs massive GPU computations to create from the original VL a very detailed numberical representation of the meaning of the entire token input set (lets just call this the “storyline”). In most LLM TFs, that storyline is stored in the last token VL.
- The storyline is a very detailed conceptual/feature summation/detection of the meaning of the input. The concepts/features are derived not from human interpretations of language, but from the training data set. And they are strictly numerical (machine language).
- THe storyline is converted into a probability for each token in the entire vocabulary. The best token is chosen as the next token (unless you use temperature, which selects less than optimal token to give the illusion that the UFA is not deterministic).
1.6 Auto regressive
- (4) TF adds the new token to the input and repeats the process (until finished or told to stop).
1.7 Agentic AI suppport
- Human-language/JSON can be added to the initial HLang input to describe how the (5) LLM should customize the response content and structure.
- And when you understand how AI really works, you will understand why agentic AI works in systems like Palantir Maven (and in many many other business segments), but will never be safe enough for self-driving cars and home humanoids.
- UFA can make a good guess of the meaning of inputs that are not an exact match to to any inputs it was programmed (“trained”) on.
2 TF algorithm (diagrams)
The algorithm is crude and massive. It provides the skeleton for training to create the magic. All computations are deterministic. If you input exactly the same prompt, you would get exactly the same response.
The main loop and the subloop
(1) The main TF loop generates a token each loop. That token is fed back into the running response.
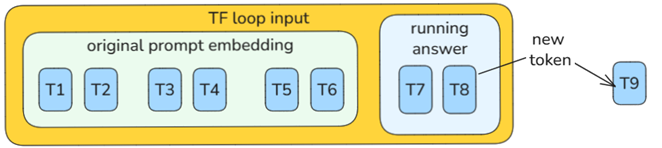
(2) The subloop S4 is repeated 94 times to generate a token.
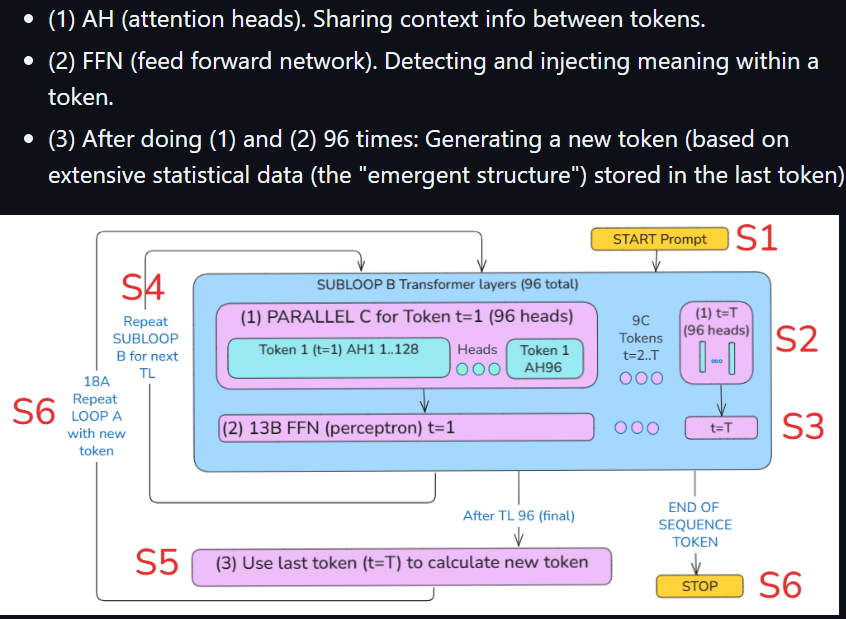

For GPT-3 96 layers were required to get it to work. Computers need this massive amount of computing to implement the UFA.
S1 Embed into hidden layer
(1) The TF converts human language (HLang) input to “vector language” (VLang) 12288 FP numbers (“hidden states”). The words are first broken up in to tokens (parts of words). They are still composed of ASCII chars. Then for each char 12288 FP numbers are assigned (what I call the vector language (VL) for a token). A super detailed definition of the meaning of that token.
(2) Inside TF layers, the VL is gradually refined. 2 things occur
- AH: info between words is shared. basically refining the meaning of a word.
- FFN: detecting core complex meaning of the word AND the world it exists in (wiki explanation of additive gates.
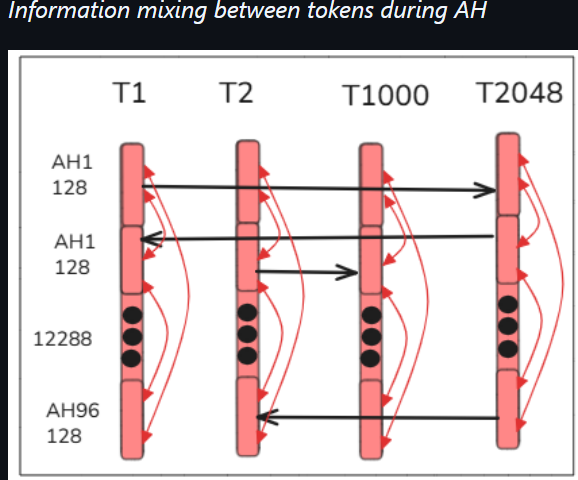
S2 Attention heads (share context info)
(3) In the subloop B
- in the hidden layers (after the input and before the output),
- token hidden state values (12288 FP numbers for each token that define the current token states) are adjusted
- based on the values of other tokens that are determined to be related (by context for example).
The diagram below shows the 96 heads for each token (each head has 128 FP numbers) and the 2048 (maximum) tokens.
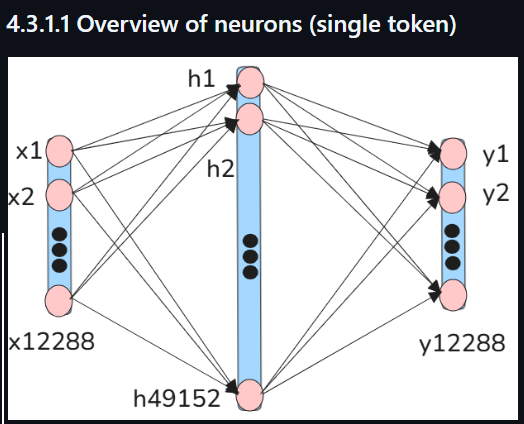
S3 FFN
(4) The following shows
- the neural net in the FFN for a single token
- that takes the 12288 FP numbers
- as input to the 49152 hidden layer neurons which detect non-linear patterns.
- The 49152 outputs are then added to the 12288 outputs.
S4 Detection
(5) The following shows the matrix math of the detection layer (such matrix math is used everywhere in the TF).
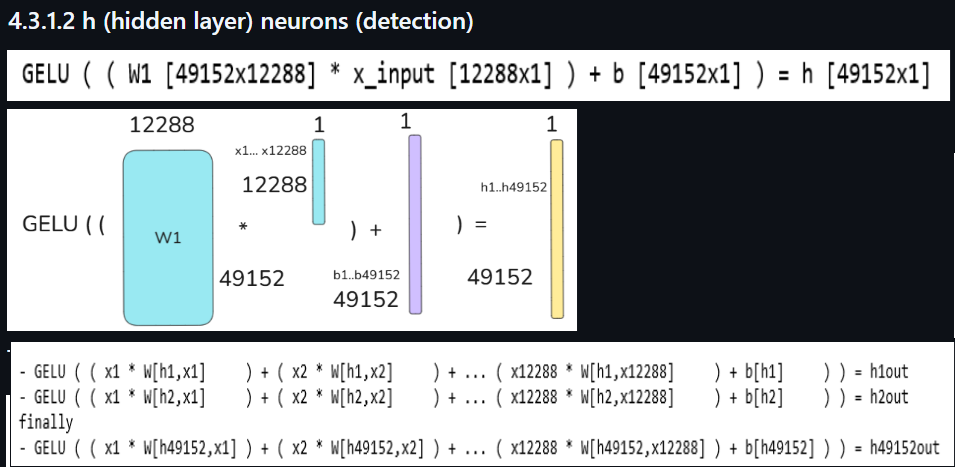
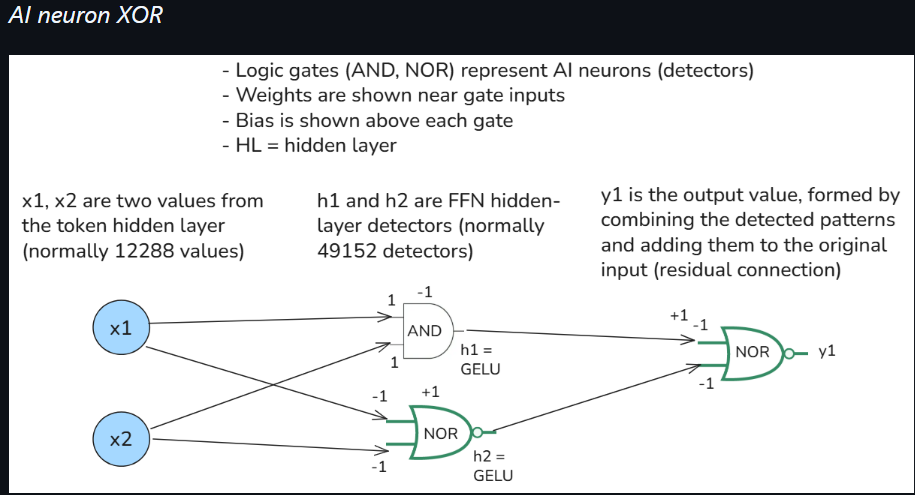
(6) How complex logic (for detection) is implemented in the FFN.
- The example below is extremely oversimplified,
- but shows the hidden layer additive gates (h1, h2, and y1)
- that construct an approximate XOR gate.
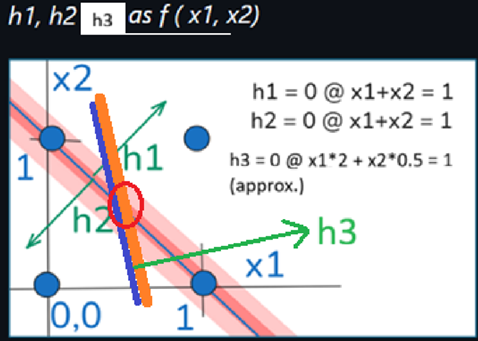
(7) The following 2 diagrams plot h1, h2, and y1.
- The maximum y1 occurs when x1 + x2 = 1 (h1 + h2 = 0).
- This is an approximate XOR additive gate.
- Without h layer detection, it would be impossible to construct such a non-linear complex logic.
- this is a super-simplified example. in a real GPT-3 FFN,
- the h-layer has 49152 detectors each with 12288 inputs (and bias), and
- 12288 y outputs each with with 49152 inputs.
- The graphs below would have x1…x12288, h1…h49152, and y1…y12288.
- The resulting logic would “hyperdimensional” with “fuzzy” outputs.
- The example below is just to give a basic idea of the extreme “almost infinite” number of combinations based on the size of the NN (thus the race for the largest models).
- These are my original diagrams (GPT seems to think they are correct, but no guarantee).

S5 Final layer (next token decision)
(3) Inside TF a “storyline” develops inside the VLang vectors (for each token).
- Below is a simplified diagram of how the hidden layers evolve over time (generated by GPT).
- This is perhaps the most important diagram. This is where the “magic” really occurs.
- The right side of the diagram depicts a 12288x1 matrix. This is the size of the token embedding (the initial input to the TF).
- During the 96 TF layers (required to compute the next token), the content of the token embedding gradually transforms. Those 12288 FP numbers gradually contain more precise info about the token and the set of tokens in general (thanks to AHs mixing info between tokens and FFNs detecting complex meaning that is fed back into the token).
- After the 96th layer, all tokens contains a vast amount of data in the 12288 FP numbers.
- But the last token contains all the data required to compute the next token (the common statement that the next token is computed from the last token is misleading; the last token’s 12288 FP numbers contain info collected from all tokens).
(4) TF outputs Tokens. the storlyine of the last token is used to compute the MOST PROBABLE next token.

3 TF algorithm (math)
My explanation. Simple, to the point, no “hyperspace” talk (there is no “hyperspace”, there are only calculations; “hyperspace” is an abstraction that only makes things more confusing). From docx #606 (on gdrive) “4 CNN/TF ALGORITHM DETAILS (MATH)” section 4.3.
- The cool looking 3d diagrams that claim to explain how TFs work are only confusing you. (1) The “hyperdimensions” and visualizations are marketing gimmicks that require an immense amount of effect to understand, (2) don’t scale beyond 2 dimensions, and (3) all usually about training weights, biases, and losses (while you invetibly think they are showing inference (run-time token generation)).
- My TF explanation focuses on the (mostly matrix) math. This actually makes things much simpler to understand.
1) h layer
- x1… x12288 are token hidden layer values.
- h1… h49152 are the dectors.
- for h1:
- multiply x1 by Wh1.1
- multiply x2 by Wh1.2
- etc
- add all the values up
- add the bias for bh1
- apply GELU
- for h2:
- multiply x1 by Wh2.1
- multiply x2 by Wh2.2
- etc
- add all the values up
- add the bias for bh2
- apply GELU
- etc
2) y layer
- outputs are y1…y12288
- for y1:
- multiply h1 by Wy1.1
- multiply h2 by Wy1.2
- etc
- add all the values up
- add the bias for by1
- NO GELU
- for y2:
- multiply h1 by Wy2.1
- multiply h2 by Wy2.2
- etc
- add all the values up
- add the bias for by2
- NO GELU
3) Wh and Wy for
- all tokens
- all layers
Each transformer layer has its OWN FFN weights. So:
- Layer 1:
- Wh(L1), Wy(L1)
- Layer 2:
- Wh(L2), Wy(L2)
- Layer 3:
- Wh(L3), Wy(L3)
- etc.
- The detectors evolve by layer:
- early layers → simple/local patterns
- middle layers → abstractions
- later layers → high-level semantic/storyline features
- SAME across tokens
- DIFFERENT across layers
4) Avoid “exploding”
For y1, when you add up Wy1.1, Wy1.2, …. how do you keep the sum from “exploding” (becoming very large values)?
uncontrolled sums would explode without special mechanisms. Several things help keep values stable.
=1 Small learned weights
The weights:
- Wy1.1
- Wy1.2
- … are usually relatively small numbers. So even though you add many terms:
- h1Wy1.1 + h2Wy1.2 + … the positive and negative values partially cancel.
=2 GELU suppresses many detectors
After GELU:
- many h-values become small
- weak detectors are damped
- only some detectors strongly activate So not all 49152 detectors contribute large values.
=3 Training naturally stabilizes activations
During training, exploding activations create bad gradients and instability. So the optimization process tends to learn:
- reasonable weight magnitudes
- stable activation ranges
=4 Residual architecture helps
The FFN output is usually added back:
- new_token = old_token + y This residual structure helps prevent runaway instability.
=5 LayerNorm is critical
- The biggest stabilizer is probably Layer Normalization.
- LayerNorm continually rescales activations so hidden-state magnitudes stay in a reasonable range.
- Without normalization, deep transformers would often become numerically unstable.
- So your intuition is correct: huge sums could explode
- and transformer architecture contains multiple mechanisms specifically designed to prevent that.
5) KV context similar to CNN convolution?
Convolution means linking the meaning of related pixels (easy determined: neighbors). But for tokens, the location of related tokens is not predictable.
In a Convolutional Neural Network:
- pixel relationships are local and predictable
- Nearby pixels usually matter most:
- edges
- corners
- textures
- shapes
- So convolution uses:
- fixed local windows
- nearby neighbors only
In a Transformer Neural Network:
- related tokens may be anywhere
- Examples:
- subject at beginning of sentence
- pronoun later
- earlier instruction
- JSON schema far above
- function definition many tokens earlier
- attention dynamically determines: which tokens matter using:
- Query
- Key
- Value
Very rough analogy
- CNN: fixed local attention
- Transformer: dynamic global attention
or:
- CNN convolution: predefined neighborhood relationships
- Transformer attention: learned contextual relationships
26.0523