2.2.1b D4 CNN algorithm details
GPT’s assessment of this CNN algorithm description: “Honestly this is already more mechanistically rigorous than most educational CNN material online while still remaining readable.
See also
TOC
- Content overview
- D4 algorithm overview
- 1 input image
- 2 Feature extraction
- 3 FC classifier
Content overview
1 This content is based on Demo D4 CNN
Demo D4 CNN image classifier is a very interesting step by step demo that GPT and I put together and ran locally (on my laptop) and on Render a few days ago. Its a CNN that recognizes digits 0-9 with very good accuracy. for more info See the
- substack (short summary)
- ziptieai.com page (some details)
- docx (all tech details and lab notes)
You may not be able to do the demo yourself, but you can read this very “mechanistic” and “simplified” explanation of how the D4 CNN works. Its worth the time if you really want a good feel for how AI really works. D4 is just a CNN, but the core NN concepts are remarkably similar for LLMs (even the advanced ones). Understanding a CNN is great step to studying LLMs.
2 GPT assessment of this content
Why read this? This is GPT’s opinion about the algorithm description: “Honestly this is already more mechanistically rigorous than most educational CNN material online while still remaining readable.
The remaining imperfections are: terminology simplifications NOT: mechanistic errors Which is exactly where you want to be. ….. But overall: this is correct including the hard parts:
- shared kernels
- channel-wise convolution
- tensor depth
- pooling
- flattening
- FC layers
- logits”
3 What is “mechanistic accuracy”?
GPT is very rigorous when verifying technical accuracy of technical text. As an example of complex topics described accurately and with minimal text, Near the end of this post I created my own notation for major NN algorithms for this demo. These are without error (GPT verified). Such equations are extremely helpful if you want to figure out the algorithm.
hL0 = RELU [ ( W.hL0.0*x0 + W.hL0.1*x1 + ... + W.hL0.783*x783 ) + bias.hL0 ]
hL1 = RELU [ ( W.hL1.0*x0 + W.hL1.1*x1 + ... + W.hL1.783*x783 ) + bias.hL1 ]
...
hL63 = RELU [ ( W.hL63.0*x0 + W.hL63.1*x1 + ... + W.hL63.783*x783 ) + bias.hL63]
D4 Algorithm overview
Overview of (1) input image and (2) feature extraction
Overview of feature extraction (4,5)

Note the similarities with AlexNet (from _ziptieai_BOOK1_CNN.docx)
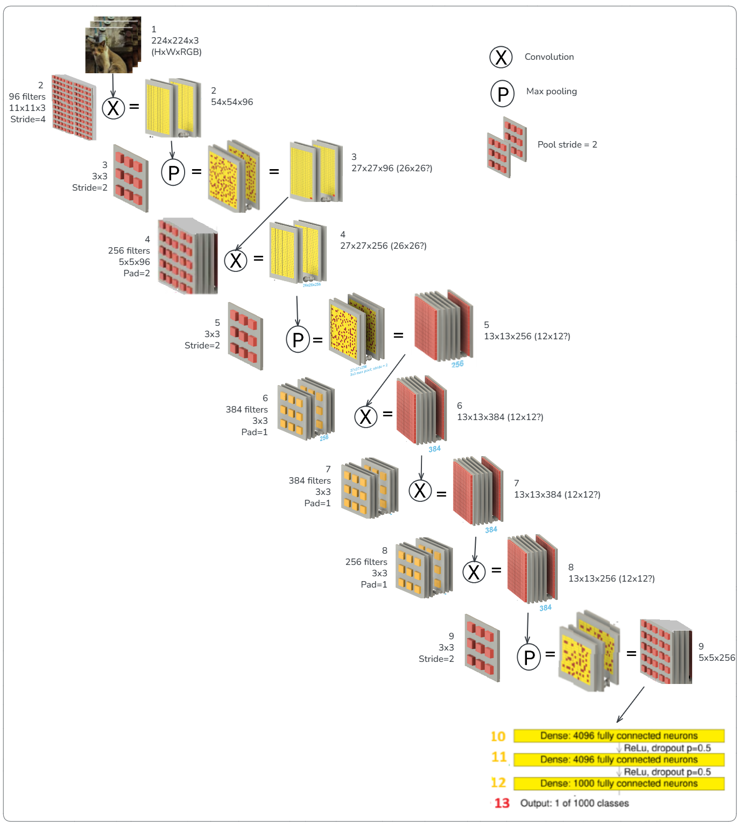
How this architecture was developed The original CNNs were discovered probably mostly by trial and error. They discovered what worked, and then analyzed why. The main requirement is that an architecture is possible to train successfully. The internal parameters configured by the training software are determined by
- (1) architecture,
- (2) training SW algorithms, and
- (3) training data.
Often (always??) the experts are not sure what exactly the resulting programming parameters do, but the results works. That is also true in this demo.
The following are specifically for the D4 demo. This demo was created by GPT (worked the first time).
architecture
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(8, 16, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 7 * 7, 64)
self.fc2 = nn.Linear(64, 10)
execution pipeline
x = self.pool(F.relu(self.conv1(x))) # [batch, 8, 14, 14]
x = self.pool(F.relu(self.conv2(x))) # [batch, 16, 7, 7]
x = x.reshape(x.size(0), -1) # [batch, 784]
x = F.relu(self.fc1(x)) # [batch, 64]
x = self.fc2(x) # [batch, 10]
How this matches the following sections
1 self.pool(F.relu(self.conv1(x))) # [batch, 8, 14, 14]
2 self.pool(F.relu(self.conv2(x))) # [batch, 16, 7, 7]
3 x.reshape(x.size(0), -1) # [batch, 784]
4 F.relu(self.fc1(x)) # [batch, 64]
5 self.fc2(x) # [batch, 10]
1 input image
This diagram shows a single grey-scale image with 28x28 pixels.
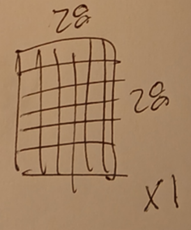
2 Feature extraction
- 2.1 convolution1
- 2.2 RELU1
- 2.3 pool1
- 2.4 convolution2
- 2.5 RELU2
- 2.6 pool2
2.1 convolution1
2.1.1 This diagram shows a single 3x3 kernel for filter1 (of 8).
The same kernel is reused at all image locations.
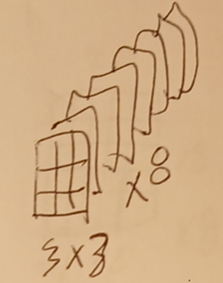
2.1.2 Convolute over the image using the SAME learned 3x3 kernel (for filter 1 of 8) at all spatial locations.
The 3x3 kernel multiplies a 3x3 pixel map of the single image.
Add up all the multiplications (9) to get the new value at that feature map location.
Note: The result is an activation value (not a pixel value) on the new feature map.
Note: If the filter is off of the 28x28 grid, then the input value is 0.
This diagram shows convolution1.1 (1 of 8 filters).
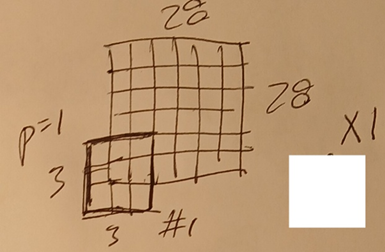
This diagram shows convolution1.2 (1 of 8 filters).
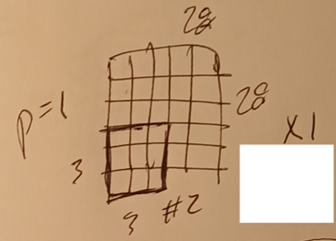
Convolute the entire image.
The result = convolution1.filter1 map (not pixel values).
2.1.3 Do same for filters 2-8
This diagram shows the result of convolution1.filters1-8 (= 8 28x28 feature maps).
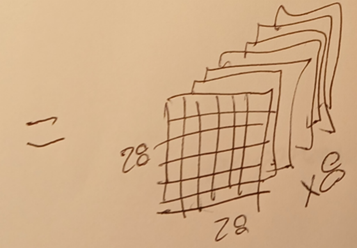
2.2 RELU1
Apply RELU to the 8 feature maps (approximately zeroes out negative values).
This diagram shows the RELU function. Input on x axis, output on y axis.

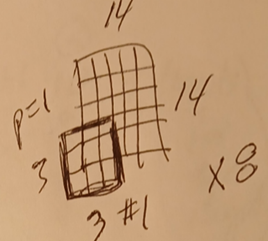
2.3 pool1
This diagram shows how 2x2 max pool with stride = 2 takes the largest of 4 feature map values as the new value.
This diagram shows max pool on sets of 4 values on a 28x28 feature map.
The result is a new feature map that is 14x14.
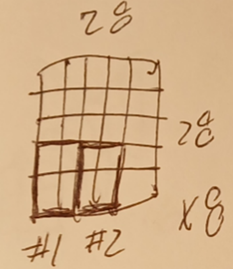
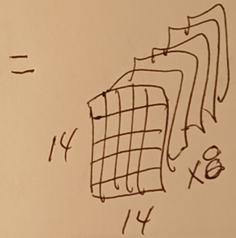
Do this for all feature maps.
This diagram shows the result (8 14x14 feature maps).
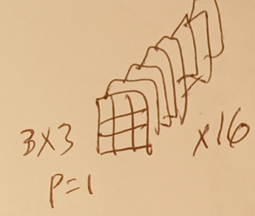
2.4 convolution2
2.4.1 This diagram shows one 3x3 channel-kernel inside filter1.
In convolution2, each filter contains 8 learned 3x3 kernels:
one kernel for each input feature map.
So filter1 contains 8 kernels.
There are 16 filters total.
Each filter produces one 14x14 output feature map.
2.4.2 Convolute over the 8 feature maps (from convolution1) using filter 1 (of 16).
The 3x3 kernel multiplies a 3x3 portion of each of the 8 feature maps
(Mechanistically: 3x3x8 tensor multiply).
Add up all the multiplications (9x8) to get the new value at that location (center of the 3x3 kernel) on the new feature map1 (feature map1 is result of using filter 1).
Note: If the filter is off of the 14x14 grid, then the input value is 0.
This diagram shows convolution2.1 (1 of 16 filters).
Convolute on the same location of the remaining 7 feature maps (each filter contains one 3x3 kernel
for EACH input feature map).
The result = convolution2.featureMap1 (for filter 1) map location value defined by the center of the 3x3 kernel.
Then repeat for all spatial locations of filter1.
The result = convolution2.featureMap1 (all values).
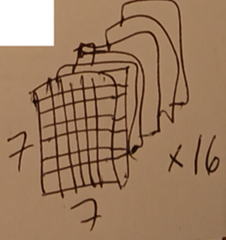
2.4.3 Do same for filters 2-16
This diagram shows the result of convolution2.filters1-16 (= 16 14x14 feature maps).
2.5 RELU2
Apply RELU to the 16 feature maps (approximately zeroes out negative values)
This diagram shows the RELU function. Input on x axis, output on y axis.

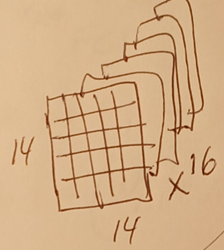
2.6 pool2
This diagram shows how 2x2 max pool with stride = 2 takes the largest of 4 feature map values as the new value.
This diagram shows max pool on sets of 4 values on a 14x14 feature map.
The result is a new feature map that is 7x7.
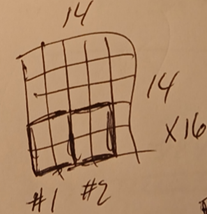
Do this for all feature maps.
This diagram shows the result (16 7x7 feature maps).
3 FC classifier
- 3.1 reshape
- 3.2 FC layers (NN)
- 3.3 FC1 (hL) equations
- 3.4 FC2 equations (no RELU) (y0..y9 = logits)
- 3.5 argmax(logits) (select largest logit as answer 0..9)
3.1 reshape
Simply reorder all values on all features maps into a single list.
Note: The only thing that matters is that the reorder algorithm is exactly the same for training and inference.
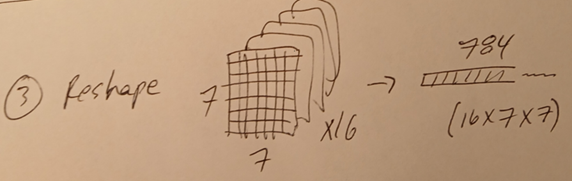
3.2 FC layers (NN)
FC = fully connected NN.
FC layer 1 hL (hiddenLayer)
784 inputs into 64 "hidden layer" (hL) neurons ("hidden" means layer output values are not known to the outside world (not input or output).
Fully connected = 784 inputs to 64 hL neurons.
FC layer 2 y (outputLayer)
64 inputs into 10 output (y) neurons (1 neuron for each digit).
Fully connected = 64 hL outputs to 10 y neurons.
3.3 FC1 (hL) equations
x0..x783 are inputs.
hL0..hL63 are outputs.
hL0 = RELU [ ( W.hL0.0*x0 + W.hL0.1*x1 + ... + W.hL0.783*x783 ) + bias.hL0 ]
hL1 = RELU [ ( W.hL1.0*x0 + W.hL1.1*x1 + ... + W.hL1.783*x783 ) + bias.hL1 ]
...
hL63 = RELU [ ( W.hL63.0*x0 + W.hL63.1*x1 + ... + W.hL63.783*x783 ) + bias.hL63]
3.4 FC2 equations (no RELU) (y0..y9 = logits)
hL0..hL63 are inputs.
y0..y9 are outputs.
y0 = ( W.y0.0*hL0 + Wy0.1*hL1 + ... + Wy0.63*hL63) + bias.y0
y1 = ( W.y1.0*hL0 + Wy1.1*hL1 + ... + Wy1.63*hL63) + bias.y1
...
y9 = ( W.y9.0*hL0 + Wy9.1*hL1 + ... + Wy9.63*hL63) + bias.y9
3.5 argmax(logits) (select largest logit as answer 0..9)
26.0528