2.2 CNNs
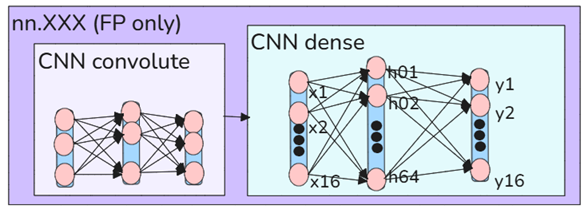
2.2.0 CNN concepts (26.0616)
The core of CNNs:
- Convolutions (localized spatial filters)
- NNs
See _ziptieai_book1_CNN.docx on the Gdrive.
D4: 2.2.1 D4 CNN image classifier (26.0528)
Runs on render (CPU mode).
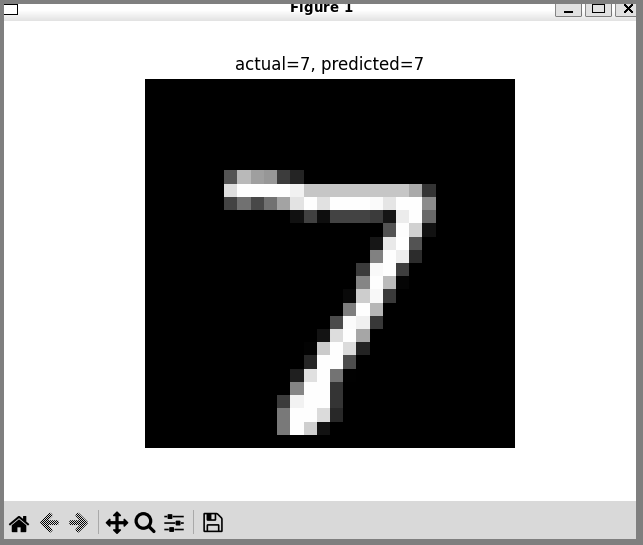
D4b: 2.2.1b D4 CNN algorithm details (26.0528)
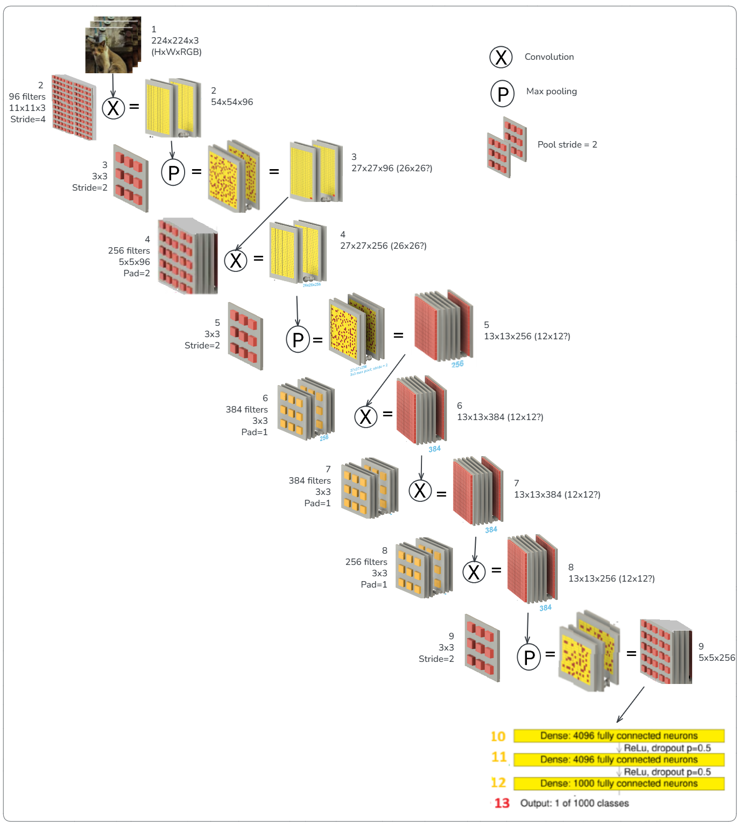
D9: 2.2.2 D9 CNN defect detector (26.0606)

D10: 2.2.3 D10 CNN feature map visualization (26.0606)
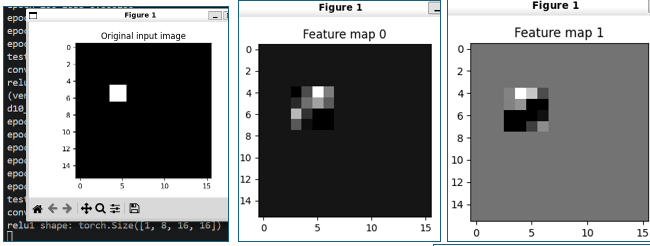
26.0616 (0529)