2.3.6.1 D5 Tiny TF
This a demo of a DIY transformer (using various PyTorch libraries). Shows the key workflows (training/inference).
See also
- 2.3.6.1b D5 tiny TF algorithm details. Describes code line-by-line with conceptual diagrams.
- #607_2.1_core_NNs_.docx. Lab notes.
- _ziptieai_BOOK2_LLM.docx the Gdrive.
TOC
- 1 Output
- 2 PY scripts
- 3 Render deploy (TODO).
1 Output
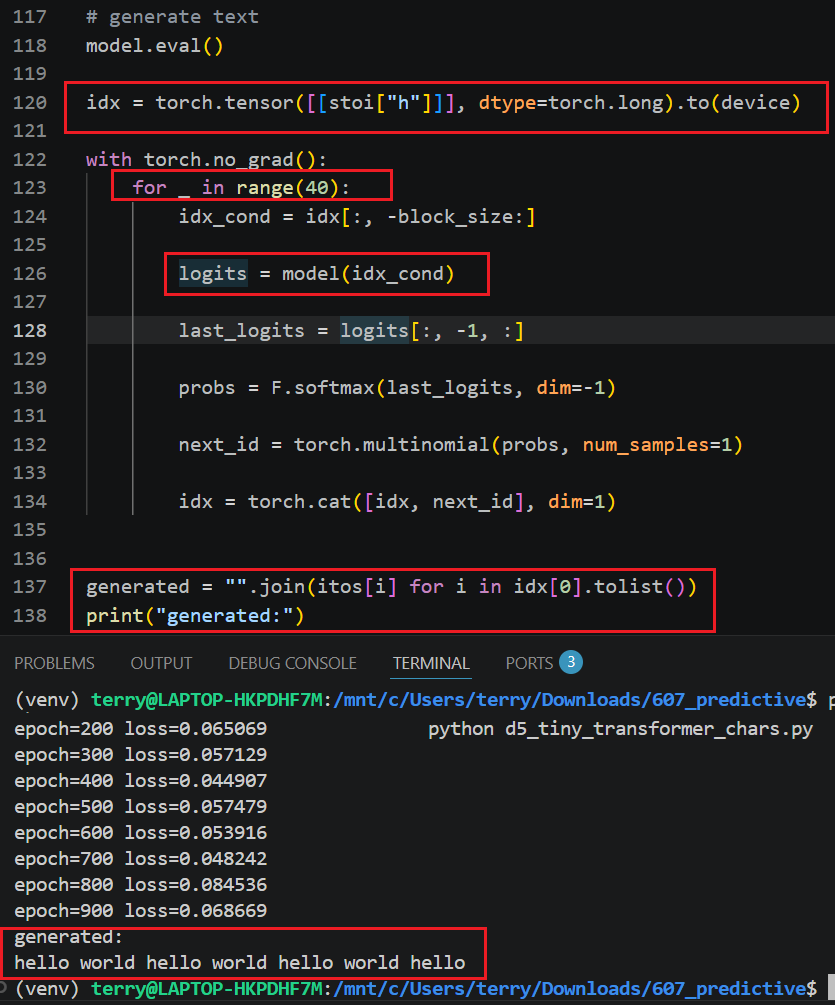
Diagram below shows the inference loop:
- Input prompt “h”
- Run 40 loops (add 40 letters (demo uses letters as tokens))
- Run loop interference (“model(idx_cond)”)
- At end of loop: Join and print.
- Result: “hello world hello world hello world hello”
2 PY script
# d5_tiny_transformer_chars.py
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
device = "cuda" if torch.cuda.is_available() else "cpu"
print("device:", device)
# -----------------------------
# D5 Tiny Transformer Demo
# character-level next-token prediction
# -----------------------------
text = "hello world hello world hello world "
chars = sorted(list(set(text)))
vocab_size = len(chars)
stoi = {ch: i for i, ch in enumerate(chars)}
itos = {i: ch for ch, i in stoi.items()}
data = torch.tensor([stoi[ch] for ch in text], dtype=torch.long).to(device)
block_size = 8
embed_dim = 16
num_epochs = 1000
def get_batch():
ix = torch.randint(0, len(data) - block_size - 1, (16,), device=device)
X = torch.stack([data[i:i + block_size] for i in ix])
Y = torch.stack([data[i + 1:i + block_size + 1] for i in ix])
return X, Y
class TinyTransformer(nn.Module):
def __init__(self):
super().__init__()
self.token_embed = nn.Embedding(vocab_size, embed_dim)
self.pos_embed = nn.Embedding(block_size, embed_dim)
self.q = nn.Linear(embed_dim, embed_dim)
self.k = nn.Linear(embed_dim, embed_dim)
self.v = nn.Linear(embed_dim, embed_dim)
self.ffn = nn.Sequential(
nn.Linear(embed_dim, 64),
nn.ReLU(),
nn.Linear(64, embed_dim),
)
self.out = nn.Linear(embed_dim, vocab_size)
def forward(self, idx):
B, T = idx.shape
token_vecs = self.token_embed(idx)
positions = torch.arange(T, device=device)
pos_vecs = self.pos_embed(positions)
x = token_vecs + pos_vecs
Q = self.q(x)
K = self.k(x)
V = self.v(x)
scores = Q @ K.transpose(-2, -1)
scores = scores / math.sqrt(embed_dim)
mask = torch.tril(torch.ones(T, T, device=device))
scores = scores.masked_fill(mask == 0, float("-inf"))
weights = F.softmax(scores, dim=-1)
context = weights @ V
x = x + context
x = x + self.ffn(x)
logits = self.out(x)
return logits
model = TinyTransformer().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(num_epochs):
X, Y = get_batch()
logits = model(X)
B, T, C = logits.shape
loss = loss_fn(
logits.reshape(B * T, C),
Y.reshape(B * T),
)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"epoch={epoch} loss={loss.item():.6f}")
# generate text
model.eval()
idx = torch.tensor([[stoi["h"]]], dtype=torch.long).to(device)
with torch.no_grad():
for _ in range(40):
idx_cond = idx[:, -block_size:]
logits = model(idx_cond)
last_logits = logits[:, -1, :]
probs = F.softmax(last_logits, dim=-1)
next_id = torch.multinomial(probs, num_samples=1)
idx = torch.cat([idx, next_id], dim=1)
generated = "".join(itos[i] for i in idx[0].tolist())
print("generated:")
print(generated)
3 Render deploy
(TODO)
3.1.3 Tiny TF (D5)
(WIP)
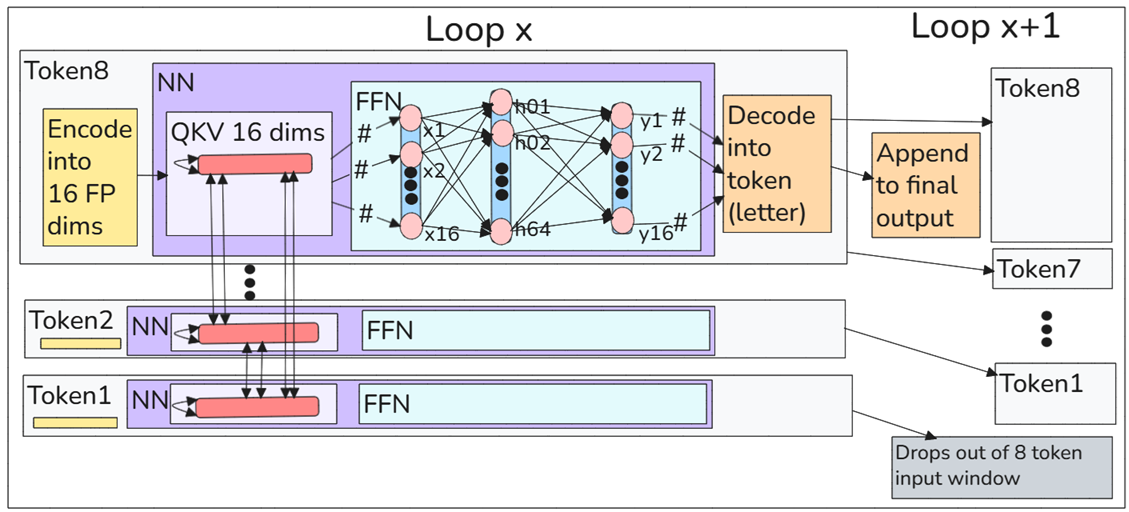
In D5 (diagram below):
- Loop 1
- Input the letter “h” (T1).
- Infer. Result = “e”.
- Loop 2
- Input the letters “h”, “e” (T1,T2).
- Infer. Result = “l”.
- ……
- Loop 8
- Input the letters “h”, “e”, “l”, “l”, “o”, “ “, “w”, “o”, (T1…T8).
- Infer. Result = “r”.
- Loop 9
- Input the letters “e”, “l”, “l”, “o”, “ “, “w”, “o”, “r” (T1…T8).
- …………
26.0616 (0603)