(2) LLMs
This page describes
- 1 LLM stack demos. I planned to spend a lot of time on this, but at some point came to the conclusion that time would be better spent elsewhere. In any case, knowing the basic is quite important. Its not that difficult to install a smaller model on your local PC, and it does have benefits.
- 2 LLM transformer (TF) training. Training is something most of us will never do (Palantir uses standard models; they do no customized training). But its the main driving factor in the design of LLM transformers.
- 3 LLM internal Agent. A deterministic (non-AI, not GPU-based) control loop inside the LLM that is the interface between the LLM transformer (TF) and the outside (of the LLM) world.
- 4 LLM (GPT-3) TF (transformer) algorithm. Its a lot of work to grasp the basics of the entire algorithm, but even a partial understanding helps you to understand the nature of the core TF component: Massive brute force computation. In GPT-3 generation of a single token requires on the order of 10^15 (a million billion) computations (and GPT-3 is much smaller than the latest models).
See also:
- Core AI (LLM) concepts (wiki page) explains in detail GPT-3 transformer algorithms.
- Core AI (LLM) misconceptions describes a chat that GPT and I had recently.
1 LLM stack demos
My focus at one point was on LLMs. I thought that that was going to be the market focus. There is a lot of value in being able to deploy and fine-tune your own LLMs, but for most of us these skills will not be used often.
The wiki page “AI LLM stacks” (a bit chaotic after a recent wiki reorganization) lists the following subpages are of interest:
- 2.2 Demo deployments (HF, CloudFlare, etc)
- 2.3 Youtube demos. I did a lot of YouTube demos. Way back then (2025, a long time ago in AI-time) I had still not make the transition to working totally with LLMs (GPT) to learn new tech.
- 2.4 GPT/Copilot demos (a few demos)
- 2.6 Agent/LLM input docs (RAG demo)
2 LLM transformer training
See also Core AI (LLM) misconceptions (website page) describes a chat that GPT and I had recently that started off about training misconceptions.
Training is something most of us will never do (Palantir uses standard models; they do no customized training). But its the second heading for a good reason: Training is the defining aspect of model transformer (TF) design (section 4 below describes GPT-3 TF design).
Training is actually a complex programming process (it is not training in the human sense). Input data is fed through the TF, and the the TF internal parameters (weights and biases) are adjusted so that the output more closely matches the intended output. The input and required output are all taken from huge sets of human generated text.
The main point is: No human does any of the programming. No human is deciding the values of weights and biases. Its all automated. And training can fail. Since its a neural network (NN), the neurons are all interconnected. When you change the value of a weight and/or bias (there are 175 billion of them in GPT-3), it can effect the input/output combinations you trained earlier. Its as much of an art than a science.
This is important to understand for several reasons. (1) You appreciate that a TF is a universal function approximator (UFA). It can take an input combination that it was never trained on and (after a massive number of statistical calculations) compute the best matching output (based on its training). (2) The tradeoff is that the TF is approximating. That’s why LLMs always warned you that they can make mistakes.
This, by the way, (3) has nothing to do with how human process language. Understanding this is not useless theory. Its vital for understanding what you can expect from AI in an application. This is why in Palanatir AI is a “helpful assitant”, not the (a) central control loop or (b) the human who actually makes critical final decisions.

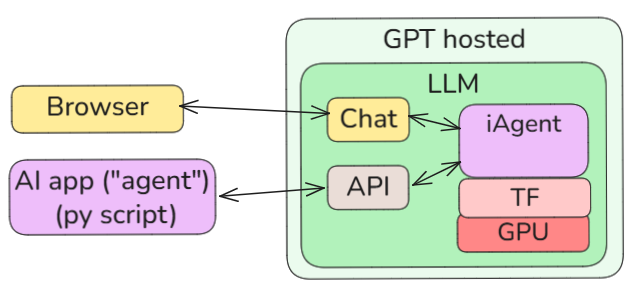
3 LLM Internal Agent
The term “agent” normally means a deterministic (non-AI, not GPU-based) control loop that is the “caretaker” or interface between the LLM model and the outside world. However, there is also an agent (what I call an internal agent or “iAgent”) in the LLM that is the interface between the transformer (TF) and the outside (of the LLM) world. Again, as with training, understanding this helps to understand the core nature of what an LLM and an agent is. An (external) agent is to some extent just an extension or a partner of the internal agent.
4 LLM (GPT-3) TF (transformer) algorithm
The following shows selected screenshots from the wiki page Core AI concepts. These diagram are my own, and depict my interpretation of the GPT-3 algorithm. Its much more complex than what these few diagrams depict. But it gives you an appreciation of the vast complexity of TF calculations.
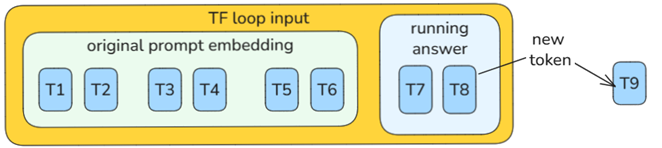
4.1 The main loop and the subloop
(1) The main TF loop generates a token each loop. That token is fed back into the running response.
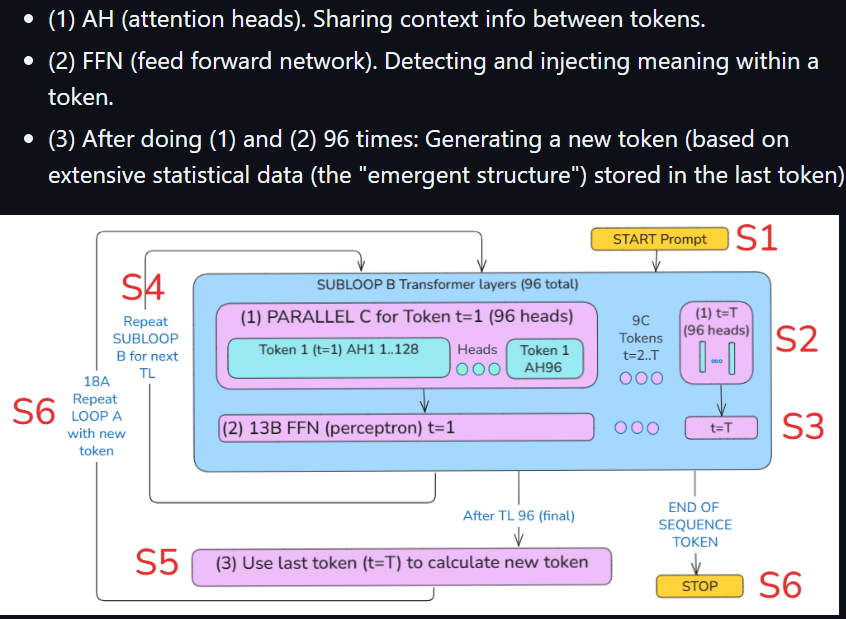
(2) The subloop S4 is repeated 94 times to generate a token.

4.2 Attention heads (share context info)
(3) In the subloop B (1) in the hidden layers (after the input and before the output), token hidden state values (12288 FP numbers for each token that define the current token states) are adjusted based on the values of other tokens that are determined to be related (by context for example). The diagram below shows the 96 heads for each token (each head has 128 FP numbers) and the 2048 (maximum) tokens.
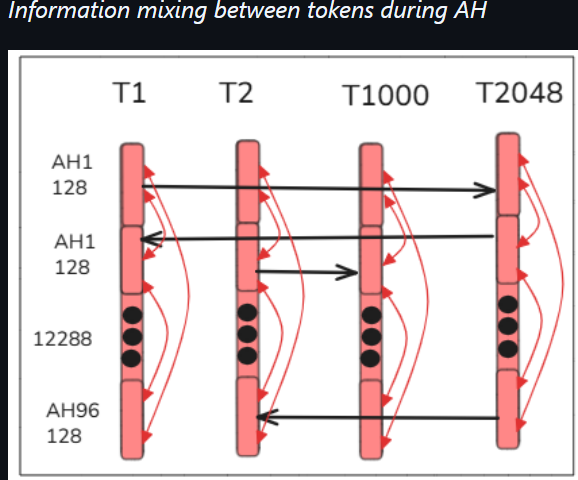
4.3 Attention heads (share context info)
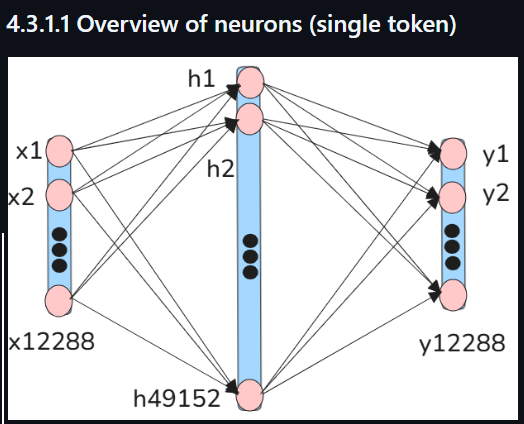
(4) The following shows the neural net in the FFN for a single token that takes the 12288 FP numbers as input to the 49152 hidden layer neurons which detect non-linear patterns. The 49152 outputs are then added to the 12288 outputs.
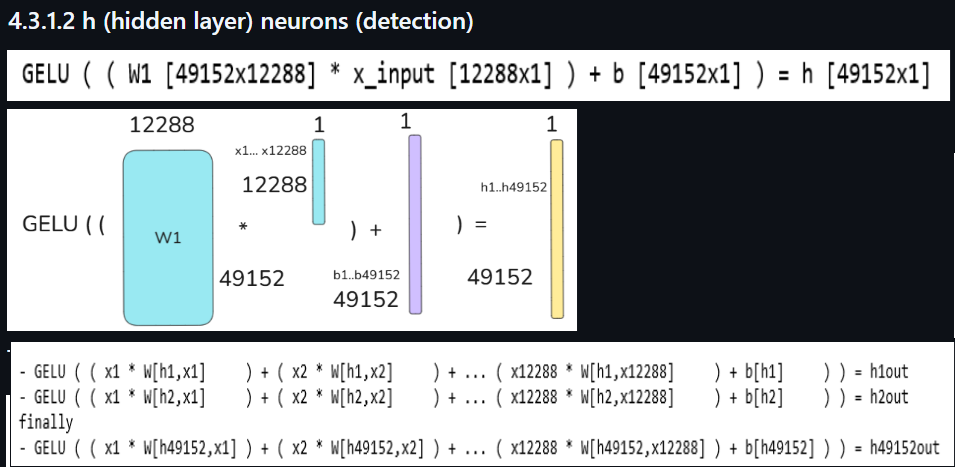
(5) The following shows the matrix math of the detection layer (such matrix math is used everywhere in the TF).
(6) How complex logic (for detection) is implemented in the FFN. The example below is extremely oversimplified, but shows the hidden layer additive gates (h1, h2, and y1) that construct an approximate XOR gate. h1 and h2
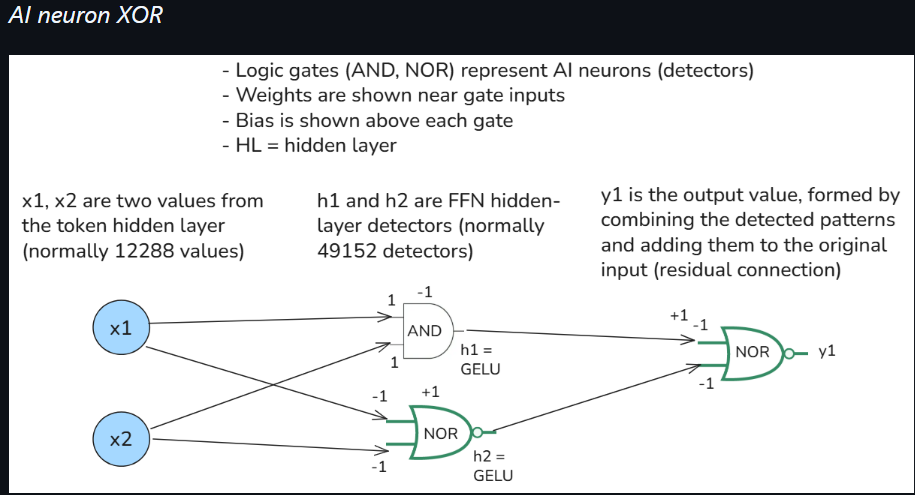
(7) The following 2 diagrams plot h1, h2, and y1. The maximum y1 occurs when x1 + x2 = 1 (h1 + h2 = 0). This is an approximate XOR additive gate. The main point is: Without h layer detection, it would be impossible to construct such a non-linear complex logic. Note that this is a super-simplified example. Note that in a real GPT-3 FFN, the h-layer has 49152 detectors each with 12288 inputs (and bias), and 12288 y outputs each with with 49152 inputs. The graphs below would have x1…x12288, h1…h49152, and y1…y12288. The resulting logic would “hyperdimensional” with “fuzzy” outputs. The example below is just to give a basic idea of the extreme “almost infinite” number of combinations. This enables an “almost infinite” number of combinations to be modeled, and even more “almost infinite” as the model gets larger (thus the race for the largest models). Note: These are my original diagrams and original demo. I believe they are correct, but the only “expert” I have consulted with is GPT.

4.4 Final layer (next token decision)
(8) A simplified diagram of how the hidden layers evolve over time (generated by GPT). This is perhaps the most important diagram. This is where the “magic” really occurs. The right side of the diagram depicts a 12288x1 matrix. This is the size of the token embedding (the initial input to the TF). During the 96 TF layers (required to compute the next token), the content of the token embedding gradually transforms. Those 12288 FP numbers gradually contain more precise info about the token and the set of tokens in general (thanks to AHs mixing info between tokens and FFNs detecting complex meaning that is fed back into the token).
After the 96th layer, all tokens contains a vast amount of data in the 12288 FP numbers. But the last token contains all the data required to compute the next token (the common statement that the next token is computed from the last token is misleading; the last token’s 12288 FP numbers contain info collected from all tokens).

26.0426