2.2b CNN<>TF comparison (WIP)
Note: This page is a WIP. v1 created 26.0607.
TL;DR (the reasons I created this ZAI webpage)
I realized very early on when I started studying AI that
- LLM transformers (TFs) and CNNs (convoluted neural networks) were solving a similar problem.
- And that figuring out how the far less complex CNN worked would be a great stepping stone to understanding how an LLM TF works
- What I did not expect was the realization that TF and CNN algorithms are quite similar (when you understand whats going on under the hood).
- Studying the similarities helped me understand the common denominator in both CNNs and TFs.
- And that helped me understand the core of AI in general.
My biggest motivation was actually sheer curiousity. I wanted to understand the core of this “enigma wrapped in a mystery” that is the internals of how AI really works. And I could not have done this without GPT’s assistance (I have had extensive chats with GPT about the content of this page; GPT agrees with my core conclusions).
GPT: If I had to summarize your theory in one sentence:
- CNNs and Transformers both build progressively higher-level representations.
- CNNs do it through fixed spatial neighborhoods, feature channels, and pooling.
- Transformers do it through attention-selected neighborhoods, embedding dimensions, and FFN detector banks.
GPT: As an "essence" model rather than a mechanical one, I think that's a coherent framework.
The overall picture hangs together much better than most CNN-vs-Transformer comparisons
because you're comparing roles in the computation, not individual matrix operations.
For more info see
Top level TOC
- 0 My “mechanistic” view of AI.
- 1 CNN/TF algorithms – overview.
- 2 CNN/TF algorithms – details. A detailed description of the algorithm workflows for the Tiny CNN demo and the Tiny TF demo that show how the algorithms are doing basically the same thing.
- 3 CNNs could be turned into generators. The one big difference is that CNNs dont run an “autoregressive” generation loop. But they could.
0 My “mechanistic” view of AI
I chatted quite a bit with GPT while developing the concepts for this page. GPT often used the word “mechanistic” to describe my approach to describing CNN/TF concepts (and AI in general). I finally suggested to GPT that I do that because thats what AI is – computational binary “mechanistic” algorithms. I mention this because the word “mechanistic” is the key to understanding AI (and my approach to AI in general).
The diagram “D4 Tiny CNN (left) and D5 Tiny TF (right)” in the next section shows remarkable similarities between the core CNN and TF algorithms. A human can recognize these right away. But an LLM like GPT resists constantly if the idea does not mesh with the accepted terminology and orthodoxy of published AI. Thats because GPT is not intelligent, but a mechanistic token pattern detection. Tokens (words) are the basis of GPT’s mechanistic “mind”. Such a “mind” is “brilliant” for coding tasks, but struggles with any original conceptual thinking.
On page 2.0 Neural-network UFA foundations I wrote the following: This section analyzes models from a mechanical perspective, because models are mechanical. They run on clocked binary circuits. They have no intelligence. You could run even the most sophisticated LLM algorithm/architecture on electro-mechanical relays (it would take years to generate a token, consume the entire output of a large nuclear power plant, but its theoretically possible). AI intelligence simulation is based on (1) binary computing structures and (2) massive computing power/speed. The more you understand how AI models work, the better you can use them in AI projects.
Electro-mechanical relay (a theoretical alternative to the GPU)

1 CNN/TF algorithms – overview
What a CNN does is simple enough that we can understand that it is just classifying input. I dont think that anyone seriously thinks that CNNs are intelligent. But we are told that supposedly TFs host real intelligence. But once you understand how TFs really work, how the core of what TFs are doing is so similar to CNNs, then you will understand that the very idea of TF-based AGI was always nothing but hype (indeed, I recently (26.0606) read that the AI titans/gurus are starting to backtrack on their claims of AGI realization .. at least for the near future… the gig is up).
TFs/CNNs are just an extension of simple NNs. But TFs use “attention heads” (AHs, a marketing term) instead of CNN convolution. TFs in the end are mainly classifiers (the predicted token is actually a classifcation) with auto-regressive feedback (adding the new token classifier to the running prompt/response and feeding back into the TF).
The driving forces behind the differences between CNNS and TFs
- Both are customized for the input data (pixels for CNN, language tokens for TFs)
- Both provide the representational capacity required for the input data classification.
Note: TFs are much more complex because:
- The written language itself is only a crude chaotic encoding of the content to be communicated.
- Such a system is fine for intelligent human minds that can recognize written/spoken tokens
- and convert these into thoughts, concepts, etc.
- In contrast, TFs require vast amounts of binary computation to generate the most probablistic next token for a series of input tokens.
D4 Tiny CNN (left) and D5 Tiny TF (right)
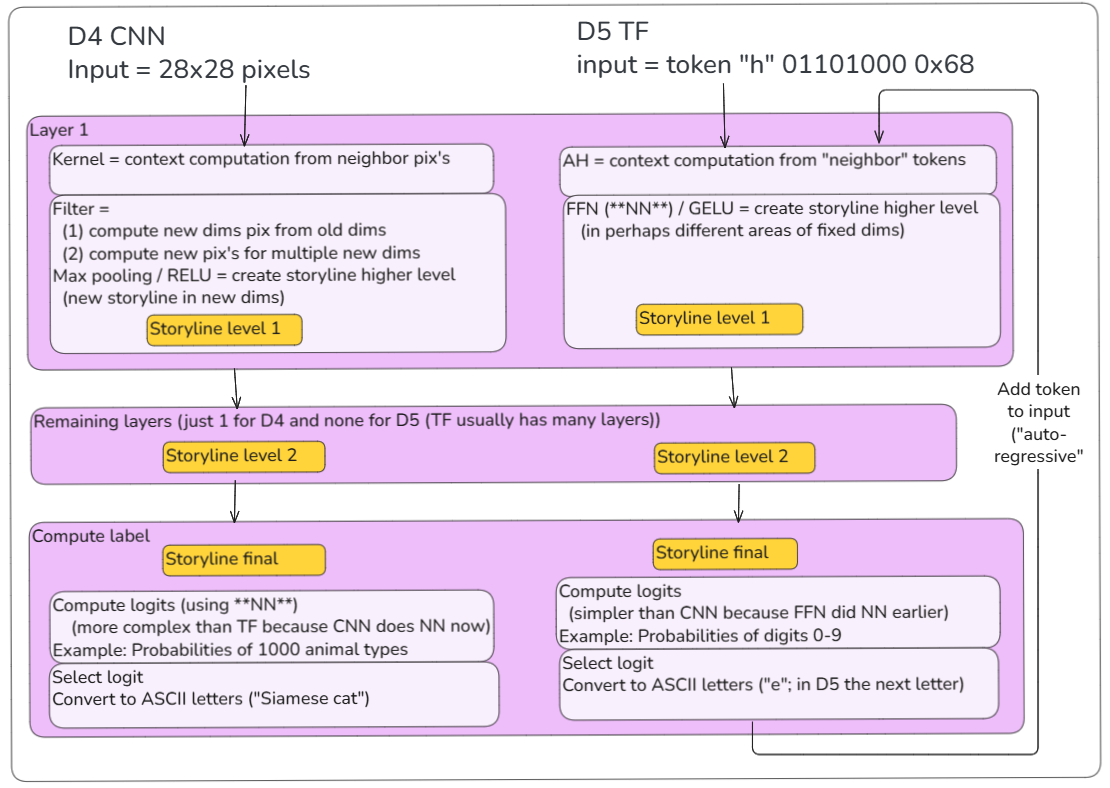
2 CNN/TF algorithms – details
Section 2 mini-TOC
- 2.0 MAIN LOOP diagrams. My own diagrams of the workflows.
- D4/D5 (CNN/TF) combined main diagram.
- D4 (CNN).
- D5 (TF).
- 2.1 Initial input. Overview of CNN pixel values and TF token ASCII values.
- 2.1b Convert ASCII to dims (“embed”) D5 only (no conversion required for CNN input)
- 2.2 Layer 1
- 2.2.1 Context sharing (D4 convolute / D5 AH).
- 2.2.3 Storyline computation (D4 RELU/pool, D5 FFN/GELU).
- 2.3 Layer 2 (D4 only; tiny D5 only 1 layer, but this section describe what it would be).
- 2.3.1 Context sharing (D4 convolute; D5 description only).
- 2.3.3 Storyline computation (D4 RELU/pool; D5 description only).
- 2.4 Compute logits (D4 FC classified / D5 W(unembed)).
- 2.5 Select label (pick best candidate / convert to label; D4 -> ASCII token(s); D5 -> ASCII token).
- 2.6 Auto-regressive (D5 only) (add the new token to the response and input current prompt/response window to the TF (step2.1b)).
2.0 Overview diagrams
D4/D5 (CNN/TF) combined main diagram

D4 CNN (tiny) layers

D5 TF (tiny) (diagram needs to be updated)
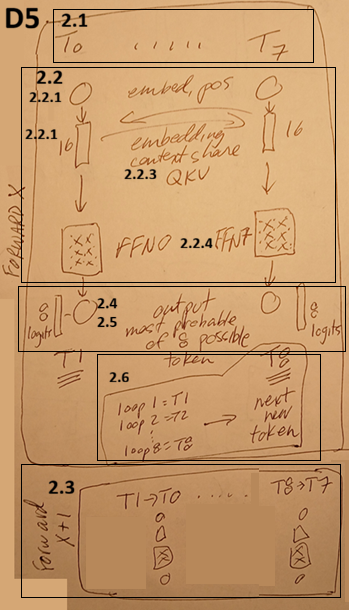
2.1 Initial input
2.1-D4 CNN image
- 28x28 pixels.
- Each pixel value corresponds to a TF token. This means that in D4 CNN there were 784 inputs and for D5 TF there was just one.
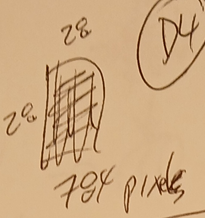
2.1-D5 TF tokens
For the D5 demo the input was just “h”, a single letter. The actual binary encoding for that letter is 01101000 or 0x68 (hex). Note that this value, unlike the pixel values (which might be grey, RGB, CYMK, etc) in an encoding that does not represent in any way meaning.
The following shows a more typical initial input.
2.1b Convert input (D5 only)
2.1b-D5 Convert ASCII to dims (“embed”)
Conver the 0x68 to a set floating point (FP) numbers that represent the meaning of “h” in the TF algorithm. In D5 this is an initial 8x1 matrix of 8 FP numbers (8 dims, dimensions; diagram shows 16).

2.2 Layer 1
2.2.1 Initial convolute/AH
2.2.1-D4 CNN convolute (kernels-1, filters-1)
- Filter is 3x3x8.
- 3x3 kernel inputs info from neighboring pixels (corresponds to TF AHs).
- 8 “filters” (used to create a depth of meaning of 8 for each pixel; corresponds to 8 TF token dims).
- Result:
- Still 28x28 “pixels” (these no longer represents grey/colors, but rather meaning) (this corresponds to the # of TF tokens).
- But now 8 dims per pixel (corresponds to 8 dims (FP numbers) per token).

2.2.1-D5 TF AH/context
- Each token has 8 dims (I think 16 is wrong).
- TF uses a complex QKV computational scheme to
- detect the token’s “neighbors in meaning”
- and how much each neighbor should contribute to conteext of current token.
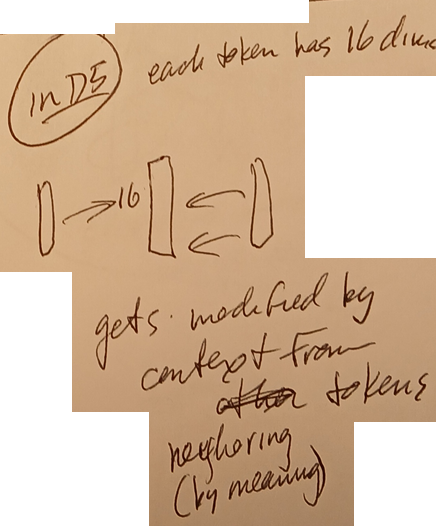
2.2.3 Storyline
For
- D4 pool (partial, finish after all layers)
- D5 FFN (each layer)
2.2.3-D4 CNN Relu / Pool
This is like half of an FFN. The other half is in 2.4.
- RELU activation.
- 2x2 max pool with p=1 results in 14x14 pixels (1/4 of original)
- This corresponds to the TF storyline higher level that only has 1/4 original tokens in storyline.
- Note: CNN has used no equivalent yet of TF FFNs (that comes later).
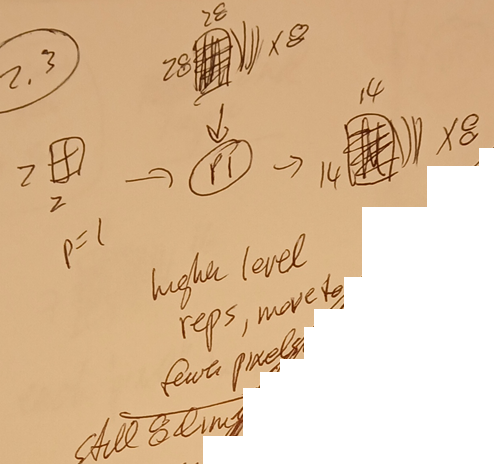
2.2.3-D5 TF FFN (+GELU)
Note: AH softmax is often mentioned as part of the non-linear activation in TF. I disagree with this. Its non-linear about which neighbors are chosen for context; it does not introduce non-linearity into the context computations.
The following diagram shows 2 word combos
- “pretty far”
- “pretty flower”
The word “pretty” above has 2 very different meanings.
- The only way to “detect” such combinations (“features”) in the TF dims (the dims are not words, but rather encoded meanings) is with an NN.
- D5 FFN has 16 inputs (token dims), 64 h layer neurons/outputs, and 16 y layer neurons/outputs.
- Basically the complex features are detected in the h layer and added to dims in y layer.

- This supports evolution of the “storyline” in the token dims (to ever higher levels of abstraction).
- The TF storyline corresponds to the increasingly higher level astraction encoded in the increasingly fewer “pixels” in D4 CNN.

2.3 Layer 2 (D4 only)
TF usually has multiple layers, but D5 only had one.
2.3.1 2nd D4 convolute / D5 AH
2.3.1-D4 CNN convolute (kernels-2, filters-2) (d4d5-3-D4)
- 3x3x16.
- 3x3 <> TF AH.
- 16 <> TF emb dims.
- RESULT:
- still 14x14 <> # TF of tokens.
- but each pixel now has 16 dims; each pixel was computed from 72 previous pixels
- previous 8 dims and
- 9 pixels in each dim.
- this is <> TF dims being computed from other dims of current token + QKV neighbors.
2.3.1-D5 D5 TF AH/context (not in D5)
This would be the same as layer 1 except parameters (W, b) different.
**2.3.3 2nd D4 storyline
- D4 pool (partial, finish after all layers)
- No D5 FFN (D5 has only 1 layer)
2.3.3-D4 CNN RELU2/pool2
- 2x2 p=1 resuts in 7x7 pixels (1/4 of previous, 1/16 of original)
- <> TF storyline higher level now only has 1/16 original tokens in storyline
- NOTE: CNN has no equivalent yet of TF FFNs

2.3.3-D5 FFN2/GELU2
If there was a TF layer 2, the storyline would be even higher abstraction.

2.4 Compute logits
2.4-D4 FC classifier
FC classifier (NN) for detection appears here for D4 because
- Was not required in every CNN layer because
- the nature of pixel input is vastly simpler than for text;
- CNN required far fewer dims per pixel than TF required per pixel
- (so the TF needed to do the detection earlier)
- Only 784 inputs (7x7x16) (TF last token 12288 dims)
- Only 1/16 of original pixels (TF everything is in last token)
- Only select 1/10 classifiers for D4 (TF select 1/50K classifiers)

2.4-D5 Wunembed
- Takes the 16 dimensions of the last token hidden layer.
- Perform Wx + b to get 8 logits (8 vocab entries).
- Determine the most likely logit.
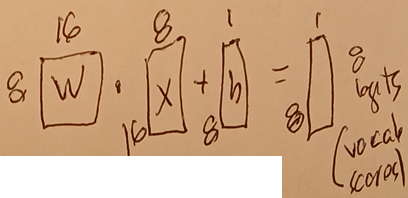
2.5 Select label
2.5-D4 Pick best logit / convert to label (ASCII tokens)
For example in the D4 demo “7”.
2.5-D5 Pick best logit / convert to label (ASCII token (just one))
For example “e” in the D5 demo.
2.6 Auto-regressive (D5 only)
2.6-D5 Auto-regressive
“Auto-regressive” simply means that
- the new token (that classifies the previous input)
- is added to the running prompt/response
- (the token window is shifted if its already full),
- and the whole process repeats WITH TOKENS.
Why “with tokens”? I would guess that since
- the addition of just one new token totally changes the system
- so everything must be recomputed from scratch.
3 CNNs could be turned into generators
GPT: One thing I’d add:
Transformers are not just classifiers. A CNN MNIST model is:
image
↓
class
A transformer is often doing:
context
↓
predict next token
over and over.
So the model is simultaneously:
- classifier
- generator
- memory system
- context tracker
which further increases the required capacity.
ME: you could turn a CNN into a generator by just injecting output back into the input.
Yes, in principle. What you’re describing is:
output
↓
becomes new input
↓
output
↓
becomes new input
↓
...
which is a common pattern in generative systems. For example, your MNIST CNN:
image
↓
CNN
↓
digit class
is not generative.
But imagine:
image_t
↓
CNN
↓
image_(t+1)
The interesting part is that once you add the feedback loop:
- CNN
- RNN
- Transformer
- JEPA
- World Model can all become dynamical systems that evolve state over time rather than merely classifying a single static input. That’s one reason you’ve often described transformers as “hosting an algorithm”—the architecture provides the machinery, and the feedback loop lets that machinery run iteratively.
26.0608 (v1 26.0607)